Next generation nanopores

6th December 2024
With the help of AI, nanopore sequencing can reliably read ultra-long sequences of DNA, RNA and many base-pair modifications. The next goal? DIY sequencing of DNA, proteins and entire human genomes in 15 minutes
Ten years ago, Oxford Nanopore launched the MinION, the company’s pocket-sized sequencer aimed at enabling anyone to perform rough-and-ready DNA analysis, anywhere. Fast, cheap and requiring minimal sample prep, the devices were soon being used everywhere from student hackspaces to off-grid research expeditions in far-flung places, including space.
However, there was one crucial problem: accuracy. The first generation of MinIONs typically read just 70-80% of DNA base pairs in a sequence correctly, while researchers could expect 99.9% from existing industry-standard sequencing. It limited nanopore sequencing to resource-limited or educational settings, or research scenarios where high-resolution reads were not important.
But the accuracy of nanopore sequencing has improved over the last decade. Much of this is due to the use of machine learning (ML) in the algorithms that ‘read’ the tiny signals made as strands of DNA pass through nanopores. With nanopore sequencing’s ability to read ultra-long DNA and RNA sequences, as well as a growing range of base pair modifications and structural genetic elements, all without the need for amplification, nanopore sequencing is now being used across all areas of the life sciences, even in demanding specialties such as clinical diagnostics and pharmaceutical quality testing.
 Astronaut Kate Rubins using nanopore sequencing on the ISS
Astronaut Kate Rubins using nanopore sequencing on the ISS
Oxford Nanopore has even bigger ambitions for the years ahead, including a device that can read entire human genomes, accurately, in under 15 minutes, and a device that allows non-expert users to sequence their DNA with nothing more than a cotton swab.
Deamer’s daydream
The concept of nanopore sequencing can be traced back to 1989, when biologist Professor David Deamer, then at UC Davis, had a strange idea while sitting in traffic, which he later sketched out in a notebook. He wondered if a pore protein, embedded in a membrane, might create specific signatures of ionic charge as different nucleotides passed through its nanoscopic channel. The pore protein, or nanopore, would in effect be a sensor, issuing a different signal for each type of nucleotide in a DNA sequence.
After discussing with colleagues years later, experiments on ‘nanopore sensing’ began in 1993 and were first described in a paper in 1996¹ using a pore protein called ɑ-hemolysin derived from Staphylococcus aureus. This early nanopore sensor was able to just about distinguish the signals made by DNA or RNA strands of different sizes.
In 2001, Professor Hagan Bayley’s laboratory in Oxford described a working nanopore sensor² that could differentiate between small DNA strands (up to 30 nucleotides long) differing by a single base substitution. However, the DNA tended to fly through the nanopores so quickly it was difficult to distinguish the signals of individual nucleotides.
Speed reader
In 2005, Oxford Nanopore was founded (originally as Oxford Nanolabs) to make commercial nanopore sequencing a reality. The chemistry of the protein pore and its substrate were refined, a bespoke electronics platform was developed to pick up and analyse the minute currents generated as nucleotides passed through, and various biochemical methods were developed to pull DNA strands through the nanopore at a more controlled speed.
By 2011, a ‘basecalling algorithm’ had been finalised to decode the tiny signals generated by each nucleotide passing through the pore, effectively ‘reading’ DNA or RNA sequences in real time as it whizzed through.
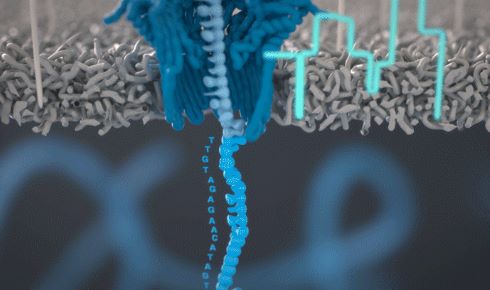 An Oxford Nanopore diagram illustrating the fluctuations of ionic charge created as different nucleotides pass through a protein pore.
An Oxford Nanopore diagram illustrating the fluctuations of ionic charge created as different nucleotides pass through a protein pore.
When the first commercial nanopore sequencer was released in 2015, its tiny size, speed and ability to read long strands of DNA were revolutionary. But its accuracy was not. The signals given off by each type of nucleotide actually differ in different contexts – for example, the signal differs depending on what the nucleotides before and after it are. The basecalling algorithms could not always understand these variations and hence would inaccurately call certain nucleotides in certain sequences.
Oxford Nanopore and academic groups soon began to use deep learning tools, such as hidden Markov models and recurrent neural networks, to train their basecalling algorithms. Comparing vast amounts of signal data with known sequences, the deep-learning-driven algorithms were then able to make far more accurate predictions of the sequences passing through. Alongside refinements in pore protein chemistry, they have helped improve accuracy of reads to over 97%, a figure that is continually increasing as the algorithms are retrained and updated.
Nanopore applications
This rise in accuracy has led to a surge in the number of ways nanopore sequencing is being used in the life sciences. At Oxford Nanopore’s four-day annual conference in London earlier this year, an entire day was devoted to clinical and biopharma applications of nanopore sequencing. One of the most spectacular involved the experimental use of sequencing during live brain surgery. Professor Pieter Wesseling, of the Princess Máxima Center for Pediatric Oncology, Utrecht, Netherlands, described how nanopore sequencing was performed during almost 50 surgeries of central nervous system tumours³. This provided a rapid molecular subclassification of the tumour during the operation, helping to inform his strategy for resection and helping to minimise the risk of neurological damage. The conference also heard how rapid nanopore sequencing is enabling clinicians to robustly identify drug-resistant Mycobacterium tuberculosis from patient samples in under 24 hours, where it once took weeks, and how nanopore sequencing is being used to build on-the-ground genomic surveillance systems for infectious disease across vast and resource-poor areas, among many other interesting uses⁴.
The ability to read ultra-long DNA sequences is also proving to be useful in understanding and treating disease. For example, nanopore sequencing is enabling clinicians to test for multiple rare diseases at once, rather than putting patients through a journey of one genetic disease test after another. Ultra-long read sequences are also useful for understanding complex cancers and deducing personalised treatments.
 Nanopore sequencing has allowed DNA and RNA analysis to be performed off-grid during fieldwork and expeditions - such as here in the Gobi Desert. Image courtesy of Oxford Nanopore Technologies.
Nanopore sequencing has allowed DNA and RNA analysis to be performed off-grid during fieldwork and expeditions - such as here in the Gobi Desert. Image courtesy of Oxford Nanopore Technologies.
Meanwhile, the ability to read RNA directly, without amplification or reverse transcription, is proving useful in the real-time quality testing of pharmaceutical products such as mRNA vaccines. And nanopore sequencing’s portability continues to see it used in low-resource or remote field settings – for example, in biodiversity and zoonotic disease surveillance.
Expanding ambitions
Deep learning and artificial intelligence, now a central part of Oxford Nanopore’s basecalling algorithms and workflows, has enabled the development of devices that can read 400 base pairs of DNA or RNA every second (BPS). It’s a long way from the days when researchers were doing everything they could to slow strands down, often to as little as 30BPS, in order to reduce the ‘signal blur’ of nucleotides passing through too rapidly.
The number of base pair modifications these devices can identify and detect is also expanding as more and more modifications are discovered and found to be important in biological development and disease. There are now almost 50 different modifications of RNA alone that can be identified using nanopore sequencing, with more being added all the time. Ever-more sophisticated analysis of the signals issuing from the nanopore also means structural elements or shapes created by DNA (such as G-quadruplexes) can be detected. These structural elements are thought to play a key role in how genes are regulated and transcribed by cells.
 The accuracy of nanopore sequencing has improved over the last decade
The accuracy of nanopore sequencing has improved over the last decade
The company has also developed an automated liquid-handling robot to prepare and sequence samples without the need for hands-on laboratory work. Further down the line, it hopes to roll out a portable ‘sample to answer’ device, which comes with prefilled reagents and can extract, prep and analyse DNA from a specimen as raw as a swab. At the higher end of its device range, it is working towards a new high-throughput device with over 100,000 pore channels (compared with the MinION’s 512) that could result in ‘15-minute human genomes’. In the words of Oxford Nanopore’s chief technology officer, Clive Brown, the aim is to enable researchers to process “mega long-reads through one cell, one chemistry, and one data type”.
The company has one more goal in its aim to allow the analysis of “anything, by anyone, anywhere” protein sequencing. While representatives of the company are tight-lipped about progress towards this goal, it is a matter of when, not if. A growing number of researchers, from the UK to China, are working on the nanopore sequencing of proteins, hoping to revolutionise how the sequence of a given peptide or protein is determined. Nanopore sequencing would enable the sequencing of extremely low-abundance proteins without the need for labelling, enrichment or fragmentation as required in existing methods.
Proteins are far more complex than DNA or RNA sequences, of course, with 20 possible amino acids to detect, rather than just four types of nucleotide, plus a range of post-translational modifications of those amino acids, and structural variants such as isomers and enantiomers. The major challenges to this technology involve unravelling an intricately folded protein so that a single strand sequence can pass through the pore and how to control the movement of that strand as it passes through. Finally, the actual sequencing will depend on the development of sophisticated algorithms that can distinguish between the tiny fluctuations of different amino acids and different sequences of amino acids.
This research offers to bring all the advantages of nanopore sequencing – the speed, the long reads, the portability – to protein sequencing and experimental protein sequencing nanopores are already being used in disease diagnostics⁵. While the time scale for accurate nanopore protein sequencing is unclear, what’s certain is that machine learning and AI will continue to be key to its development – decoding the subtleties of nanopores’ ionic charge in ways that human minds likely never could.
Tom Ireland MRSB is editor of The Biologist.
1) Kasianowicz, J. J. et al. Characterization of individual polynucleotide molecules using a membrane channel. Proc. Natl. Acad. Sci. USA 93(24), 13770–13773 (1996).
2) Howorka, S. et al. Sequence-specific detection of individual DNA strands using engineered nanopores. Nat. Biotechnol. 19(7), 636–639 (2001).
3) Ultra-fast deep learned CNS tumour classification during surgery. London Calling 2024.
4) Clinical and Biopharma Day, London Calling 2024.
5) Hu, Z. L. et al. Biological nanopore approach for single-molecule protein sequencing. Chem. Int. Ed. 60, 14738 (2021).
